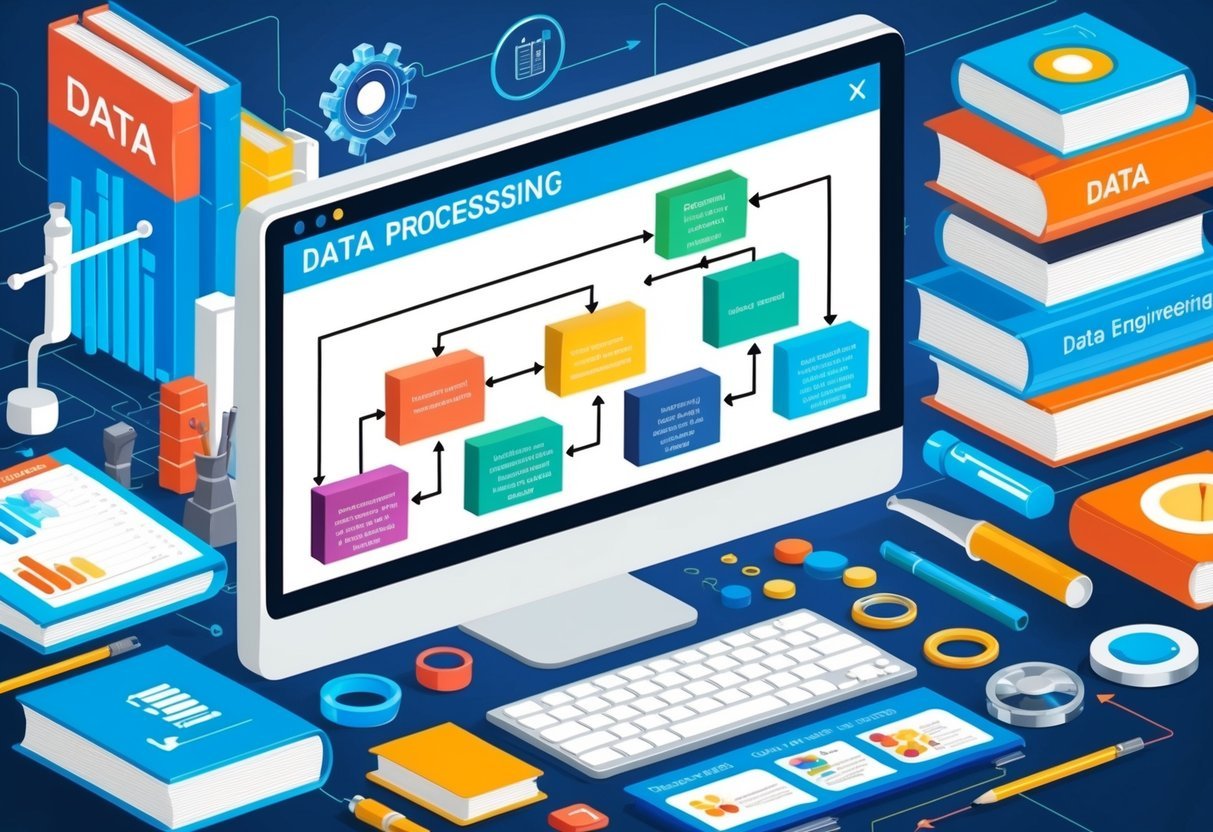
Understanding SQL Window Functions
SQL window functions are essential tools for data analysts. They allow users to perform calculations across a set of table rows that are related to the current row. They are unique because they can show both individual row data and aggregate values simultaneously. This enhances analysis efficiency and accuracy.
Defining Window Functions
Window functions are special SQL expressions used to compute values for each row in a query result set. These functions operate over a group of rows defined by the OVER clause, which specifies how to partition and order the data. Unlike aggregate functions, window functions do not collapse rows into a single result. Instead, they retain each row’s identity, providing additional insights.
Window functions include operations like running totals, moving averages, and ranked data analysis. They offer powerful ways to analyze data that are not feasible with standard aggregates. When implemented with correct syntax and logic, window functions can greatly simplify complex queries, saving time and resources in data analysis.
Types of Window Functions
There are several types of SQL window functions, each with distinct purposes. Aggregate functions, such as SUM(), AVG(), and COUNT(), compute values over a defined set of rows, returning results like totals and averages.
Ranking functions, such as RANK(), DENSE_RANK(), and ROW_NUMBER(), help assign a rank or number to each row based on certain criteria.
Value functions, including LEAD() and LAG(), are used to access data from preceding or following rows. This ability facilitates trend analysis and comparisons between current and surrounding data points. Window functions are versatile, enhancing the capabilities of SQL in processing data in meaningful ways.
The Role of Window Functions in Data Analysis
Window functions play a crucial role in data analysis by enabling analysts to write efficient and concise SQL code. They allow users to perform complex calculations without requiring multiple subqueries or temporary tables. This capability makes reports clearer and easier to maintain, reducing errors and enhancing data-driven decision-making.
By using window functions, analysts can derive insights from data distributions, track changes over time, and identify patterns. These functions expand the analytical power of SQL, making it a vital skill for data professionals aiming for streamlined, accurate data analysis. With a foundational knowledge of SQL window functions, analysts can unlock new levels of insight in their datasets.
Fundamentals of SQL Window Function Syntax
SQL window functions enable users to perform complex calculations across various rows while keeping each row’s data intact. Mastering their syntax is vital for efficient data analysis, involving understanding the basic structure and the key elements used in defining these functions.
Basic Window Function Structure
The basic structure of an SQL window function includes the function itself, followed by the OVER() clause. Window functions differ from aggregate functions because they can return multiple rows and allow operations across a specified set of rows.
Examples of window functions include ROW_NUMBER(), RANK(), and SUM(). These functions operate within a query and provide results per row in conjunction with their defined window.
Within the syntax, the OVER() clause specifies the window, meaning the set of rows the function works on. It does so by using elements like PARTITION BY to divide the result set into partitions and ORDER BY to define the sequence of rows.
Within each partition, the function is applied similarly to each row. Understanding this structure allows users to gain advanced insight into data without summarizing it entirely.
Understanding Over() Clause
The OVER() clause is critical in defining the window over which a function operates. It consists of optional elements such as PARTITION BY, ORDER BY, and a frame clause.
PARTITION BY divides the result set into smaller groups, enabling operations like ranking within each partition separately. Following this, ORDER BY determines the order of rows within each partition, influencing function output crucially.
The frame clause further narrows the set of rows the function processes. By specifying a range of rows, such as a current row and rows above or below, users can achieve precise calculations. This capability makes window functions powerful tools for data analysts, providing detailed insights without consolidating rows, ensuring flexibility in data retrieval and analysis. Utilizing resources like GeeksforGeeks enhances understanding of these functions’ applications.
Data Segmentation with Partition By
Partition By is a powerful tool in SQL that helps to segment data into distinct groups for more detailed analysis. By using it with window functions, users can calculate metrics like averages or rankings within specified groups, making it invaluable for data analysis tasks.
Grouping Data for Window Functions
The Partition By clause is often used in SQL to create groups within a dataset. This allows window functions to perform calculations on each group separately. Unlike Group By, which reduces rows by summarizing data, Partition By maintains all rows while still enabling group-based calculations.
For example, if a dataset includes sales data across multiple regions, one can use Partition By to compute the average sales in each region without collapsing the dataset into fewer rows. This maintains full data visibility while still leveraging the power of aggregation functions.
Integrating Partition By with functions like ROW_NUMBER(), RANK(), or AVG() can provide insights such as ranking items within each group or calculating moving averages. These capabilities enable more customized and detailed data analysis, supporting informed decision-making.
Practical Uses of Partition By
Partition By is especially useful in scenarios where detailed analysis is required without losing individual data points. One common application is in finance, where users calculate running totals or moving averages for specific accounts or time periods.
For instance, calculating a cumulative total of sales for each product category in a dataset allows analysts to observe trends and performance over time without collapsing the dataset. This method ensures the integrity of the data while still providing meaningful insights.
Another practical use is in ranking operations where items are ranked within their groups. Using functions like RANK() with Partition By, an analyst can determine the position of each item relative to others in the same category, which is vital for comparative analysis.
Ordering Data with Order By
The ORDER BY clause in SQL is essential for sorting data, especially when using window functions. It arranges rows based on specified criteria, influencing how calculations occur within window frames, such as ranking or aggregating data.
Sequencing Rows for Analysis
Using ORDER BY helps to sequence data rows based on defined columns. Sequencing is crucial for analytical tasks as it dictates the order in which data is processed. This can be ascendingly or descendingly.
For example, ordering sales data by date can help identify trends over time. Sorting by amount can highlight top sales. This ability to sequence rows means that analysts can find patterns or anomalies effectively.
In SQL’s window functions, the sequence determined by ORDER BY is combined with keywords like PRECEDING and FOLLOWING to define dynamic data ranges for calculations.
Implications of Order By in Window Functions
In window functions, ORDER BY defines the sequence of rows upon which functions like RANK(), ROW_NUMBER(), or SUM() operate. The order of rows influences results significantly.
For instance, ranking by score in a test dataset will yield different rankings if sorted ascendingly versus descendingly.
ORDER BY interacts with the window frame by dictating how past (PRECEDING) and future (FOLLOWING) rows are evaluated in functions.
In cases where calculations involve the CURRENT ROW, ORDER BY ensures accurate reference points. Proper ordering is fundamental to deriving meaningful insights through window functions, making understanding this clause essential for precise data analysis.
By leveraging ORDER BY, data analysts can ensure the integrity and relevance of their analyses, leading to reliable business insights.
Calculating Running Totals and Averages
Running totals and averages are essential for tracking trends and analyzing data over periods. These calculations are often used in finance and business to monitor performance and identify patterns.
Implementing Running Total Calculations
Running totals accumulate values over a series of rows in a dataset. This is particularly useful in financial statements or sales reports where cumulative figures, like year-to-date sales, need calculation.
To compute a running total, SQL window functions such as SUM are often used with the OVER clause to define the rows included in each calculation. This allows for tracking changes over time and understanding data trends clearly. For a practical example, see this guide on running totals.
Using the window function syntax SUM(column) OVER (ORDER BY another_column) can help calculate the running total efficiently. Understanding how to set the partition correctly allows the user to maintain data details while gaining aggregate insights.
Understanding Running Averages
A running average provides the average of values within a moving range of data points. This is beneficial for smoothing out fluctuations and identifying overarching trends.
For instance, a company might want to evaluate performance by tracking a three-month running average of monthly sales.
The SQL function AVG combined with a window function setup, such as AVG(column) OVER (ORDER BY another_column), helps achieve this by averaging the values up to each row of interest. This makes it possible to see trends clearly as they develop over time.
Running averages are vital for assessing data over intervals, ensuring that short-term variations do not overshadow longer-term patterns. The proper application of running averages aids in making informed decisions backed by consistent data insights.
Ranking and Distribution with SQL Functions
SQL offers powerful tools for ranking and determining data distribution, allowing users to analyze datasets more effectively. These functions are critical in distinguishing rows and understanding the percentile positions within data.
Applying Ranking Functions
Ranking functions in SQL, like RANK, ROW_NUMBER, and DENSE_RANK, are essential for sorting and organizing data. These functions assign a unique value to each row in a result set based on a specified order.
-
RANK: This function assigns a rank starting from 1 to each row within a partition. If there are ties, it assigns the same rank to the tied values and skips the subsequent rank(s), which might create gaps in ranking. -
ROW_NUMBER: UnlikeRANK, this function assigns a unique row number to each row, without gaps, helping in cases where distinct numbering is necessary. -
DENSE_RANK: Similar toRANK, but without gaps between rank numbers. This means consecutive ranking numbers follow each other even if there are ties.
These functions are helpful for highlighting top results in datasets, such as listing salespeople according to sales volume.
Determining Data Distribution
To understand how data is spread across a dataset, SQL uses distribution functions like NTILE and PERCENT_RANK. These help in dividing data into ranked categories or calculating percentile positions.
-
NTILE: This function divides the result set into a specified number of roughly equal parts. Each row is assigned a bucket number, which is useful for performing inequality comparisons among groups. -
PERCENT_RANK: This calculates the relative standing of a value within a result set. It is determined using the formula(rank-1)/(number of rows - 1). It provides a fractional rank, from 0 to 1, indicating the percentage of values below a particular value.
Using these distribution functions, analysts can better visualize how values compare to one another, making insights into trends and outliers more accessible.
Leveraging Lag and Lead for Data Insights
The LAG() and LEAD() functions in SQL are essential for analyzing data in sequence. They allow for comparing values across different rows, which is particularly useful in evaluating sales trends and understanding temporal patterns within datasets. These insights can inform strategic decisions and enhance predictive analytics.
Exploring Previous and Subsequent Rows
The LAG() function lets users access data from a previous row within the same result set. This is helpful when reviewing sales records to identify fluctuations over time.
For example, by applying LAG(sale_value), one can compare current sales figures to those preceding them, providing context for growth or decline.
Similarly, the LEAD() function works in the opposite direction. It retrieves information from the row that follows, allowing analysts to look ahead in the data sequence. This can be useful in scenarios where predicting future sales patterns is necessary for business planning.
Both functions operate using a specified ordering within a partitioned dataset, helping analysts make precise evaluations. More about these functions can be seen in articles that discuss LEAD() and LAG().
Analyzing Trends with Offset Functions
Offset functions like LAG() and LEAD() are invaluable for spotting trends in sales data. By analyzing the differences between current and prior sales figures, businesses can determine patterns such as increasing, decreasing, or stable sales trends over time.
For instance, calculating the difference between sale_value and LAG(sale_value, 1) can highlight changes within specified periods. Meanwhile, LEAD() assists in forecasting potential future trends by examining upcoming data points.
Incorporating these functions into SQL queries enhances the ability to extract meaningful insights from complex datasets, aiding effective decision-making. Detailed examples and use cases of these window functions can be explored at resources like LearnSQL.com.
Advanced Analytic Functions
Advanced Analytic Functions in SQL involve using powerful techniques to extract meaningful insights from data. These functions include operations like finding the first and last values within a data set, as well as applying complex calculations with window functions.
First and Last Value Analysis
Understanding how to utilize first_value and last_value can greatly enhance data analysis. These functions allow users to pull out the first or last value in a specified data set. This can be important when identifying starting and ending points in sequential data, such as tracking inventory levels over time.
For example, using first_value() helps in pinpointing the initial stock value when analyzing inventory. Similarly, last_value() can be used to determine the final stock level, enabling businesses to make informed decisions based on trends.
These functions are especially useful in financial contexts, like monitoring the opening and closing stock prices within a specific timeframe, thus providing key indicators for investment strategies.
Complex Window Function Applications
SQL’s window functions extend beyond basic calculations, allowing for sophisticated analyses. They enable complex calculations such as running totals, moving averages, and rank-based data segmentation. By partitioning data using OVER() clauses, these functions structure data for more refined insights.
Window functions also allow for period comparisons, like analyzing sales trends by month or quarter. This can assist businesses in identifying seasonal patterns.
They help gain deeper insights without needing complex client-side programming. For example, advanced data analysis with SQL can calculate moving averages to smooth out stock fluctuations over time, supporting more stable revenue projections.
Effective Use of Aggregate Window Functions
Aggregate window functions in SQL, such as sum(), avg(), count(), min(), and max(), offer unique capabilities for analyzing data. These functions can perform calculations across data sets while retaining individual row detail. This allows for in-depth comparisons and pattern discoveries.
Beyond Basic Aggregations
Aggregate window functions allow users to perform operations over a group of rows, giving access to both detailed and summary information simultaneously.
For instance, using sum() can provide a running total, which is useful for tracking cumulative sales over time.
The avg() function, when employed with window functions, can be used to calculate a moving average for stock prices without losing individual daily data. Meanwhile, count() can help determine the frequency of specific events or actions over a specified subset of data.
Functions like min() and max() can be used to find dynamic moving ranges, such as identifying the highest and lowest temperatures over any given period.
Comparisons and Advanced Insights
Window functions also enable detailed comparisons within datasets, offering advanced insights that traditional aggregate functions do not.
For example, comparing monthly sales trends with the overall yearly trend becomes straightforward using a window function with avg().
In financial datasets, users can leverage max() and min() to track peak values over periods, such as daily stock highs. Similarly, sum() can compare current month sales to previous months without requiring multiple queries.
By using these functions, analysts can focus on specific data patterns, uncovering trends and anomalies more effectively.
SQL Window Functions in Practice
SQL window functions are essential for data analysts who need to perform complex calculations while retaining individual data rows. These functions are particularly useful for tackling real-world problems and enhancing database management skills.
Interactive Exercises and Practice Set
Engaging with interactive exercises is crucial for mastering SQL window functions. Websites like LearnSQL.com offer a variety of practice sets that walk users through different scenarios.
These exercises range from basic to advanced, providing a comprehensive platform to improve SQL skills.
By completing hands-on exercises, data analysts can better understand concepts such as partitioning data, calculating running totals, and ranking data within various segments.
This practical approach helps learners solidify their understanding and become more confident in using window functions.
Handling Real-world Problems with SQL
SQL window functions are a powerful tool for addressing real-world problems in data analysis. They allow for calculations across different partitions without losing detail, making them invaluable for database management.
In practice, data analysts can use them to analyze sales trends, identify top-performing products, or detect patterns in customer behavior.
For instance, using window functions to calculate moving averages or cumulative totals can provide deeper insights into business performance and trends.
Resources like GeeksforGeeks offer examples on how to apply these functions in realistic scenarios, aiding analysts in honing their skills to tackle everyday challenges effectively.
Understanding Time-series Data Analysis
Time-series data involves sequences of data points recorded over time, often analyzed to identify trends, patterns, and averages. Special window functions in SQL can help in exploring this data effectively, making it possible to uncover insights about moving averages, sales rank, and more.
Time-series Specific Window Functions
Time-series analysis often requires functions that handle sequences based on time intervals. SQL window functions such as LAG, LEAD, and ROW_NUMBER are commonly used in this context.
-
LAG and LEAD allow analysts to access data from previous or subsequent rows. This is essential for comparing current values with past or future points, helping in trend analysis.
-
The ROW_NUMBER function helps to order data and rank it, which is useful for identifying a sales rank. With these functions, one can generate running totals and cumulative sums to visualize data trends over time.
Analyzing Patterns and Averages
To analyze patterns in time-series data, moving averages and running averages are key tools. A moving average smooths out fluctuations by averaging subsets of data, making it easier to identify consistent trends within a noisy dataset.
Meanwhile, running averages provide a real-time calculation of averages, updating as each new data point is entered. This is particularly useful in monitoring ongoing processes like sales trends.
For example, using window functions such as AVG() can help establish averages over specific time frames, revealing important insights into the underlying patterns of the data, such as recurring trends or seasonal variations.
Optimizing and Troubleshooting Queries
When dealing with SQL queries, especially those using window functions, performance can be a concern. Understanding how to optimize these functions and troubleshoot common issues helps ensure smooth operations and accurate results.
Optimizing Window Function Performance
To improve performance, one should focus on minimizing data handling. Indexing is crucial as it speeds up data retrieval. Ensure that columns used in partitioning or ordering have appropriate indexes. This prevents full table scans, which can be time-consuming.
When writing queries, it’s helpful to eliminate unnecessary subqueries. Streamlined queries are easier for the database engine to execute and help reduce computational load.
Using more specific filters before applying window functions can also enhance performance. Narrowing down the dataset early in the query process conserves resources by only handling relevant data.
Lastly, caching intermediate results can also boost performance, especially in complex calculations.
Common Pitfalls and Solutions
One common issue is incorrect results due to unoptimized query structures. This often occurs when window functions are used without understanding. To solve this, double-check the logic and structure of the query.
Incorrect partitioning often leads to unexpected outcomes. Carefully specify the partitioning clause to ensure calculations are grouped as intended.
Ambiguous column references can be a pitfall as well. Use aliases for clarity and to prevent errors.
Improper use of the HAVING clause can also lead to complications. Remember that HAVING applies to aggregated results, which may not be directly affected by window functions. Double-check the logic and if needed, use subqueries to filter data before applying window functions.
By addressing these issues, one can ensure more reliable and efficient query performance.
Frequently Asked Questions
SQL window functions are powerful tools used in data analysis to perform calculations across related rows. They differ from other functions by allowing more complex data operations. Understanding how to implement them can greatly enhance data analysis skills.
What is the purpose of window functions in SQL for data analysis?
Window functions in SQL allow users to perform calculations across a set of rows that are related to the current row. This is beneficial for tasks like ranking, moving averages, and cumulative sums. They provide a more efficient way to handle complex data operations compared to using subqueries.
How do you implement window functions in SQL for different types of data analysis?
Implementing window functions involves using SQL keywords like OVER and PARTITION BY. These help define the window or set of rows that the function will operate on. Examples include calculating running totals or analyzing sales trends over time.
Can you provide examples of using SQL window functions to solve real-world problems?
A common use of window functions is in financial analysis, where they help track cumulative sales or expenses. They are also used for ranking items, such as listing top-performing products or employees within specific categories.
What are the key differences between window functions and other SQL functions?
Unlike aggregate functions that return a single value, window functions perform calculations across a set of rows. They retain the original row structure, allowing for more granular analysis. This makes them suitable for tasks requiring detailed data insights.
Which types of window functions are available in SQL and when should each be used?
SQL offers a variety of window functions like ROW_NUMBER(), RANK(), and SUM().
ROW_NUMBER() is useful for assigning unique rankings. Meanwhile, RANK() can handle ties by giving the same rank to equal values. Lastly, SUM() can be used for cumulative totals.
How long typically does one need to practice before they can efficiently use SQL window functions for data analysis?
The time needed to become proficient in window functions varies. With focused study and practice, one could start using them effectively in a few weeks.
Consistent practice with real data sets further accelerates this learning process.