Understanding SQL and Databases
SQL, or Structured Query Language, plays a crucial role in managing and interacting with databases. It is specifically designed to communicate with these systems and efficiently manage data.
A database is an organized collection of data. This data is stored and accessed electronically.
Databases usually contain tables, where each table has rows and columns. These rows and columns hold specific sets of information.
There are various types of Database Management Systems (DBMS). Among them, the Relational Database Management System (RDBMS) is widely used. This system organizes data into tables, which relate to one another. These relationships are key to retrieving and managing data efficiently.
In an RDBMS, data is stored using relational models. This way, data can be updated or queried easily without redundancy. SQL is used to perform operations on these databases, such as inserting, updating, deleting, or retrieving data.
Here’s a simple example table of a customer’s database:
| CustomerID | Name | City |
|---|---|---|
| 1 | Alice | New York |
| 2 | Bob | San Francisco |
SQL commands, also known as queries, are used to manage this data. For example, a basic SELECT statement retrieves specific information.
Relational databases and SQL are essential for businesses needing efficient data retrieval and management techniques. They provide a stable framework for managing large datasets and support various applications in different sectors.
Setting Up the Database Environment

Setting up your database environment involves choosing the right tools and software for your needs. Key components include selecting the type of database management system (DBMS), installing it, and using SQL interfaces to access and manage your databases.
Choosing a Database Management System
When deciding on a Database Management System, it’s important to consider factors like cost, scalability, and features.
MySQL is popular for web applications due to its versatility and open-source nature.
PostgreSQL is favored for complex queries and reliability, often used in data warehouses.
For Windows users, Microsoft SQL Server offers strong integration with other Microsoft products and robust security features. Each system has unique strengths that cater to different project needs.
Installing SQL Server, MySQL, or PostgreSQL
Installing a DBMS requires downloading and setting up the software on your system.
For SQL Server, Microsoft offers a detailed installation process, which includes selecting the edition and configuring services.
MySQL installation can be completed through platforms like WAMP or MAMP on different operating systems.
PostgreSQL provides installers for Windows, macOS, and Linux, allowing flexibility between environments. Each installation process includes configuring initial settings and testing the connection to ensure functionality.
Accessing Databases with SQL Interfaces
Once your DBMS is installed, you can interact with databases through SQL interfaces.
Tools like MySQL Workbench provide a graphical interface for database design and management.
SQL Server Management Studio (SSMS) is a comprehensive tool for SQL Server users to manage their databases efficiently with options for queries, reporting, and analysis. PostgreSQL users often use tools like pgAdmin for an intuitive interface to handle database operations.
SQL interfaces streamline database interaction, making it easier to execute commands and maintain database health.
Creating and Managing Database Tables
Creating and managing database tables is essential for organizing data efficiently in a database. Understanding the SQL syntax for creating tables and defining their structure is crucial for any database task. Key considerations include the use of the CREATE TABLE command and the specification of columns and data types.
Creating Tables with CREATE TABLE
To create a table in SQL, the CREATE TABLE command is used. This command lets users define a new database table with specified columns and data types.
For example, the command might look like:
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
HireDate DATE
);
In this example, Employees is a database table with columns defined for employee ID, first name, last name, and hire date. The PRIMARY KEY constraint on EmployeeID ensures that each employee has a unique identifier.
CREATE TABLE can include additional constraints such as FOREIGN KEY and UNIQUE to ensure data integrity.
Defining Columns and Data Types
When creating a table, defining columns with appropriate data types is essential for data integrity.
Common data types include INT for numbers, VARCHAR for variable-length text, and DATE for storing date information.
For example, choosing VARCHAR(50) allows strings of up to 50 characters, providing flexibility while managing storage efficiently. Constraints such as NOT NULL ensure that critical fields are not left empty.
Specifying accurate data types and constraints helps optimize the database structure by maintaining consistent, reliable data. Knowing when to use each data type reduces storage and improves database performance. Avoiding incorrect data types can prevent errors and support effective data management throughout database operations.
Data Manipulation Language (DML) Basics
Data Manipulation Language (DML) is essential for working with data in SQL databases. It includes commands for inserting, updating, and deleting records. These operations allow users to modify data stored in database tables, ensuring that information is current and relevant.
Inserting Data with INSERT INTO
The INSERT INTO statement is used to add new records to a database table. It specifies the table and the columns where data will be placed.
For example, INSERT INTO Employees (Name, Position, Department) VALUES ('John Doe', 'Developer', 'IT') inserts a new employee into the Employees table.
When using INSERT INTO, it is crucial to match the data types of the values with the columns. Omitting a column in the list means SQL will assume that column’s value is either null or a default, if one is set.
This statement can also be used to insert multiple rows by listing several VALUES clauses separated by a comma.
Updating Records with UPDATE Statement
To modify existing data, the UPDATE statement is used. It changes records in a table based on specified conditions, ensuring the information reflects the current state.
For example, UPDATE Employees SET Position = 'Senior Developer' WHERE Name = 'John Doe' updates John’s position.
The UPDATE statement requires the SET clause to define which columns to modify and what the new values should be. The WHERE clause is essential as it specifies the records to change; without it, all entries in the table will reflect the update.
This command effectively maintains data accuracy and keeps records up to date.
Deleting Records with DELETE Statement
The DELETE statement removes records from a table. This operation is necessary when data is no longer needed.
For instance, DELETE FROM Employees WHERE Name = 'John Doe' deletes John’s record from the Employees table.
The importance of the WHERE clause in the DELETE statement cannot be overstated. It ensures that only specific records are removed. Omitting the WHERE clause will result in the deletion of all records in the table, which might lead to data loss.
Therefore, careful use of this statement helps maintain data integrity.
Querying Data with SELECT
Querying data with the SQL SELECT statement is essential for interacting with databases. It allows users to fetch specific information and analyze data effectively.
Selecting Columns and Filtering Rows
The SELECT statement is used to read data from database tables. Users can specify particular columns using the SQL SELECT clause.
For example, SELECT column1, column2 fetches only the desired columns.
To filter records, the WHERE clause is added. For instance, SELECT * FROM employees WHERE department = 'Sales' retrieves employees from the Sales department.
The DISTINCT keyword ensures unique results, eliminating duplicates. For example, SELECT DISTINCT department fetches each department name only once, useful in large datasets.
Sorting Data with ORDER BY
Sorting is crucial for viewing data in a preferred order. The ORDER BY clause arranges records by one or more columns.
By default, it sorts in ascending order, but DESC changes it to descending.
For example, SELECT first_name, last_name FROM employees ORDER BY last_name DESC will sort employees by last name in reverse order.
Combining multiple columns in ORDER BY can create more complex sorting rules. For instance, ORDER BY department, salary first sorts by department and then by salary for ties. This allows for a clear and organized data presentation.
Aggregating Data with Functions like COUNT and SUM
Aggregation functions like COUNT and SUM provide insights by summarizing data.
COUNT calculates the number of entries, such as SELECT COUNT(*) FROM employees to find total employees in the table.
SUM adds up numeric values across records. For example, SELECT SUM(salary) FROM employees calculates the total salary expense.
This is crucial for financial reports. Combining these with GROUP BY enables category-based analysis, like SELECT department, COUNT(*) FROM employees GROUP BY department to see how many employees are in each department, offering a snapshot of organizational structure.
Filtering Data with WHERE Clause
The SQL WHERE clause is crucial for filtering data in a database. It selects rows based on specified conditions, making data retrieval precise and efficient. The following key techniques help filter data effectively: using comparison and logical operators, and leveraging keywords like LIKE, IN, and BETWEEN.
Utilizing Comparison and Logical Operators
The WHERE clause uses comparison operators such as =, !=, >, <, >=, and <= to compare values within columns. These operators enable users to filter rows that meet specific criteria.
For instance, selecting employees with salaries greater than $50,000 requires salary > 50000.
Logical operators (AND, OR, NOT) allow combining multiple conditions within a WHERE clause.
Using AND will return rows meeting all conditions, while OR will return rows if at least one condition is true. For example, finding employees in either the Sales or HR department would involve department = 'Sales' OR department = 'HR'.
Leveraging Keywords LIKE, IN, and BETWEEN
The LIKE operator is useful for pattern matching within string data. It employs wildcards like %, which represents zero or more characters, and _, representing a single character.
For example, finding customers whose names start with “M” involves name LIKE 'M%'.
The IN operator provides an efficient way to filter data by checking if a value exists in a list. For example, retrieving orders from certain years can be done with year IN (2019, 2020, 2021).
Finally, the BETWEEN operator is used for selecting ranges, such as dates or numbers. To find records within a salary range of $30,000 to $50,000, the query would be salary BETWEEN 30000 AND 50000.
Enhancing Queries with Joins

SQL joins are crucial for combining records from two or more tables based on related columns. They allow for more complex queries to retrieve data in meaningful ways.
Understanding INNER JOIN and LEFT JOIN
An INNER JOIN returns records with matching values in both tables. It’s the most common join used to combine tables where specific conditions meet on both sides.
For example, retrieving a list of students with their courses utilizes INNER JOIN between the students and courses tables.
A LEFT JOIN includes all records from the left table, with matched records from the right. Unmatched rows in the right table appear as nulls. This join is useful for identifying items like all students and their enrolled courses, including those not currently taking classes.
Exploring RIGHT JOIN and FULL OUTER JOIN
A RIGHT JOIN is similar to a LEFT JOIN but focuses on returning all records from the right table and matching rows from the left. This join helps when you want to ensure all entries from the right table, such as courses, appear regardless of student enrollment.
A FULL OUTER JOIN incorporates all records from both tables, returning rows with matches and placeholders for unmatched fields too. This join is beneficial for comprehensive reports to see students, their courses, and identify which entries lack corresponding data.
Performing CROSS JOIN and SELF JOIN
A CROSS JOIN produces a Cartesian product, resulting in all possible combinations of both table rows. It’s generally not common in practice but can be useful for scenarios such as generating all possible pairings of items from two lists.
A SELF JOIN is a table joined with itself. It’s particularly useful for querying hierarchical data, such as organizational charts, where each row relates back to another in the same table. By using aliases, it allows for tracking relationships like employees reporting to managers.
Learn more about SQL JOINs
See examples of SQL JOINs
Leveraging SQL Functions and Subqueries
SQL functions and subqueries play a crucial role in data analysis and querying tasks. Utilizing aggregate functions allows detailed analytics over datasets, while subqueries enable the formation of flexible and powerful SQL statements.
Utilizing Aggregate Functions for Analytics
Aggregate functions are helpful in summarizing large datasets. They include operations like SUM, COUNT, AVG, MIN, and MAX.
For instance, the AVG function calculates the average value of a set. In a sales database, finding the average sales revenue per region can be achieved by using this function.
Example:
SELECT region, AVG(sales) AS average_sales
FROM sales_data
GROUP BY region;
This query provides average sales by region, helping analysts spot trends and patterns quickly. Aggregate functions work closely with the GROUP BY clause to organize data into logical groups. This combination is fundamental for generating reports and insights from raw data, making analytics more efficient and precise.
Incorporating Subqueries in Queries
Subqueries, also known as nested queries, are SQL queries embedded within another query. They allow for more complex operations, such as filtering, updating, and generating intermediate results.
For example, a subquery can find employees with salaries above the average.
Example:
SELECT employee_id, name
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
This query extracts employee details where their salary exceeds the overall average. Subqueries can be used in SELECT, FROM, or WHERE clauses, each serving specific purposes. They are particularly useful when performing operations that need to reference aggregated or conditional data, adding versatility to SQL queries. Subqueries enhance SQL’s capability, making them essential for comprehensive data analysis.
Advanced Data Selection Techniques
In advanced SQL, leveraging tools like GROUP BY, HAVING, and specific functions such as CASE and EXISTS can enhance data selection capabilities. These techniques allow precise data manipulation, ensuring insightful analysis.
Using GROUP BY for Segmented Aggregations
The GROUP BY clause is essential for categorizing data into segments for aggregate calculations. By incorporating GROUP BY, you can efficiently summarize information.
For instance, calculating total sales by region enables businesses to identify geographic trends.
This clause pairs well with functions like SUM, COUNT, or AVG, allowing detailed breakdowns of datasets. Such segments reveal patterns that are otherwise hidden in raw data. When combined with the DISTINCT keyword, it ensures that duplicates do not skew results, leading to more accurate metrics and better decision-making.
Applying HAVING to Filter Aggregated Data
The HAVING clause follows GROUP BY and is used to filter results based on aggregate function conditions. Unlike WHERE, which filters rows before aggregation, HAVING works on grouped data.
For example, you might need to identify products with sales exceeding a certain threshold.
Implementing HAVING allows refined queries, which are crucial for pinpointing specific insights from aggregated data pools. This clause is especially useful in cases where multiple filtering criteria depend on summary information. Combining HAVING with GROUP BY creates powerful queries that provide targeted data views.
Working with Advanced Functions LIKE CASE and EXISTS
Functions such as CASE and EXISTS enhance SQL queries’ adaptability and intelligence.
CASE allows conditional logic, acting like an if-then-else statement within SQL queries. By using CASE, values within the results can conditionally change, adding flexibility in data representation.
For instance, you can categorize sales figures into various performance levels.
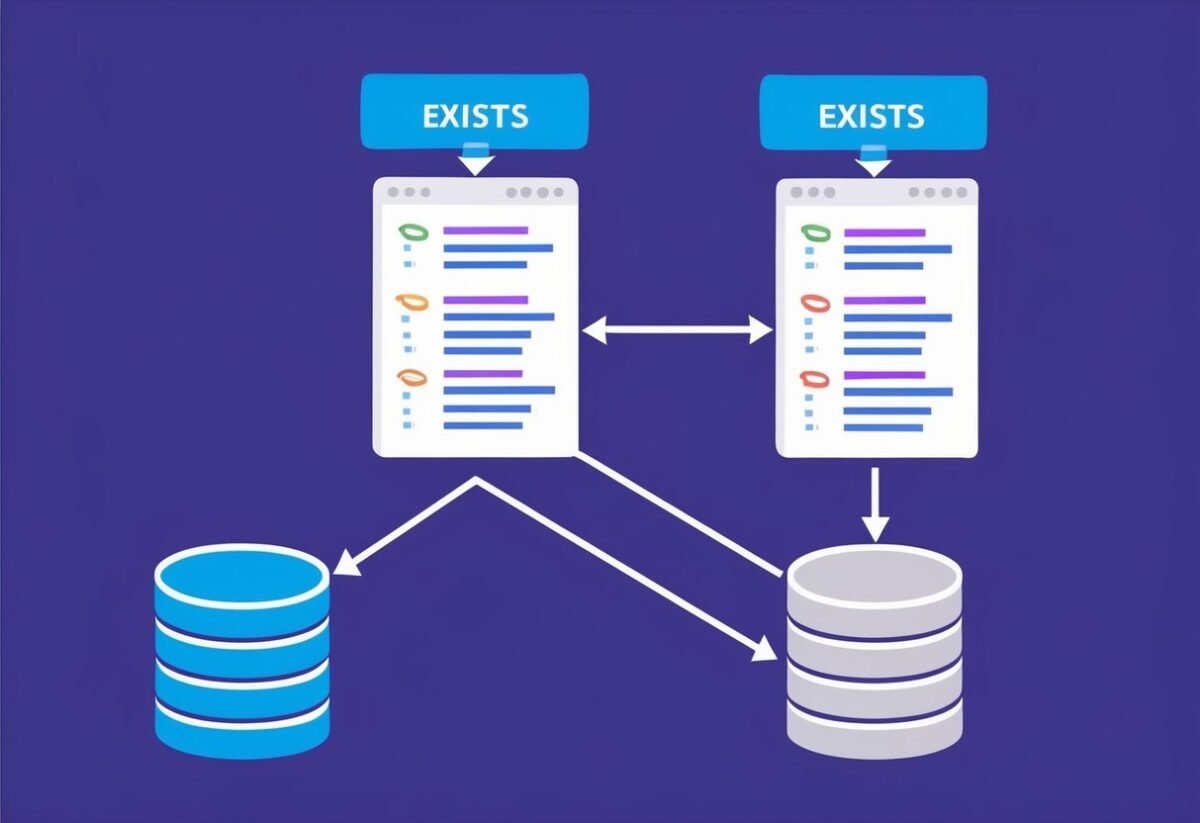
The EXISTS function checks for the presence of rows in a subquery, optimizing queries by quickly assessing whether related data meets specific conditions. This method makes for faster execution by focusing only on data that fulfills particular criteria, ensuring resource-efficient analysis.
Both functions expand SQL’s capability to sift through vast data stores, allowing users to frame queries that ask precise questions and retrieve focused answers.
Building and Using Views
Views in SQL are virtual tables that display the result of a query. They simplify complex queries by storing them in a reusable way.
To create a view, use the CREATE VIEW statement. For example:
CREATE VIEW employee_view AS
SELECT name, position
FROM employees
WHERE department = 'Sales';
This view makes it easy to access employees in the Sales department.
Reading from a view is similar to selecting from a table. Use a simple SELECT statement:
SELECT * FROM employee_view;
This retrieves all the data defined in the view.
If you need to update a view, the CREATE OR REPLACE VIEW statement allows changes without deleting it:
CREATE OR REPLACE VIEW employee_view AS
SELECT name, position, salary
FROM employees
WHERE department = 'Sales';
This update adds the salary field.
Some views can also be updated directly, but it’s important to note that not all views support direct updates. To delete a view, use the DROP VIEW statement:
DROP VIEW employee_view;
This removes the view from the database.
For a deeper dive into SQL views, including their usage and management, explore the article on creating, updating, and deleting views.
Modifying Database Structure

This section covers how to change the structure of an existing database using SQL commands. Key points include adding or changing columns with the ALTER TABLE command and removing entire tables with DROP TABLE. Each subsection will explain how these operations influence database design.
Adding and Modifying Columns with ALTER TABLE
The ALTER TABLE command allows changes in table structure without recreating the table. It’s used to add new columns, change data types, or rename columns.
For instance, adding a DateOfBirth column to a Persons table can be done using:
ALTER TABLE Persons
ADD DateOfBirth DATE;
To modify an existing column’s type or name, use similar syntax. W3Schools provides examples such as changing a column’s data type. This flexibility helps keep databases efficient and up to date with evolving data needs.
Removing Tables with DROP TABLE
The DROP TABLE command is used to delete a table and all its data from the database. This is irreversible, so it should be done with caution. Use:
DROP TABLE Customers;
This command will remove the Customers table entirely. It’s crucial for cleaning databases by removing unnecessary or outdated data structures. While powerful, using DROP TABLE inaccurately can result in critical data loss, so understanding its impact is vital for any database manager. More about this function can be found on GeeksforGeeks.
Practical SQL Tips and Best Practices

Getting started with SQL can be straightforward with some practical tips. First, it’s essential for learners to familiarize themselves with basic SQL syntax. A simple SQL cheat sheet can serve as a quick reference for common commands.
When writing SQL queries, clarity is crucial. Use formatting, such as line breaks and indentation, to make queries easy to read. This helps in identifying errors quickly and understanding the logic at a glance.
Understanding SQL concepts like JOINs and subqueries is key. They are foundational to executing complex queries.
Beginners should focus on mastering SQL fundamentals by writing and running queries in a real-time environment, which can enhance learning.
Regular SQL practice is beneficial. Platforms like SQL Tutorials and SQL Basics offer interactive ways to practice and solidify knowledge.
Learning about SQL functions can expand one’s ability to manipulate and analyze data. Functions like COUNT, SUM, and AVG are commonly used and highly useful in various scenarios.
Experimenting with multiple SQL databases such as Oracle, Sybase, and SQLite broadens exposure and improves adaptability. Each has unique features and quirks that can be valuable to know.
For aspiring data scientists or data analysts, understanding SQL fundamentals is critical. Being proficient in SQL can greatly aid in handling and interpreting data, making it a vital skill in the toolkit of programming languages.
Frequently Asked Questions

SQL is a powerful language for managing and working with data. Understanding basic commands, effective practice methods, and foundational concepts sets a strong foundation for beginners.
What are the most common SQL commands I should start with?
Begin with key SQL commands like SELECT, INSERT, UPDATE, DELETE, and CREATE. These form the basis of retrieving and modifying data.
How can beginners learn and practice SQL syntax effectively?
Beginners should practice using SQL tutorials and exercises online. Websites often provide interactive lessons to reinforce learning through hands-on experience.
What is the difference between DDL, DML, and DCL in SQL?
DDL (Data Definition Language) involves commands like CREATE and ALTER, which define database structures. DML (Data Manipulation Language) includes SELECT, INSERT, and UPDATE, impacting data. DCL (Data Control Language) commands such as GRANT and REVOKE control access to data.
Can you provide examples of basic SQL queries for a beginner?
A simple SELECT statement can retrieve data from a table, like:
SELECT * FROM Customers;
Another basic query is an INSERT statement:
INSERT INTO Customers (Name, Age) VALUES ('Alice', 30);
What resources are available for understanding SQL syntax and conventions?
Resources like LearnSQL.com and SQL Cheat Sheets provide valuable insights into syntax and conventions.
How does one structure a complex SQL query?
Structuring a complex SQL query often involves using subqueries, joins, and conditions.
Breaking down the query into smaller parts and testing each can help manage complexity.